Linear Model? or General Linear Model with Gaussian Distribution? or ANOVA? or ANCOVA? There are many names for this type of model, they all effectively mean the same thing. I am going to stick to calling it a Gaussian GLM because then there isn’t a new name for every different test. If you don’t like that, use whatever term you like, but the code and interpretation will be the same.
Data Loading - Palmer Penguins
As before lets use the Palmer penguins dataset and remove the NAs (as before NAs should never be remove without considering why there are NAs but here we will remove them for ease).
Does the flipper length of penguins change between species and between sexes?
Step One - Scienctific Model to Stats Model
Whether we use an interaction or not depends on if our scientific thought believes the relationship of Species to flipper length is different between sexes (sexual dimorphism may not be consistent across species). We shall use an interaction here as we might expect some sexual dimorphism in some species while less, no or opposite sexual dimorphism in other species. If we had good reason to expect the same sexual dimorphism across these species we would not use an interaction term.
Step Two - Resonse Variable Distribution
As you probably guessed from the title we will be using a Gaussian Distribution. However, flipper length would more technically be a Gamma distribution. It is Numeric, Continuous but cannot be Zero or Negative! Using a Gaussian distribution in this situation is okay as flipper length will not approach 0, so issues of modelling near the zero will not be a problem. This is due to our sampling and just the fact that you won’t ever be able to measure a penguins foot that is 1 mm. or probably less than 25 mm! Our lowest value is 174 in the data. One method could be to centre and scale the flipper_length_mm and model it with a Gamma distribution but this would be a lot of converting back and forth, especially when a Gaussian model will perform equally as well.
Step Three - Organising Fixed Effects
Thankfully both sex and species are already factors in the dataset so we don’t have any organising to do!
So lets apply our model. lm() is a function in base r that allows us to create a Gaussian GLM object. There is also a glm() function where we would need to define the distribution but lm() is easier to use for gaussian models. We will create a model object then we can inspect and use this model.
We could apply a linear model to almost all data but often it will not meet our assumptions.
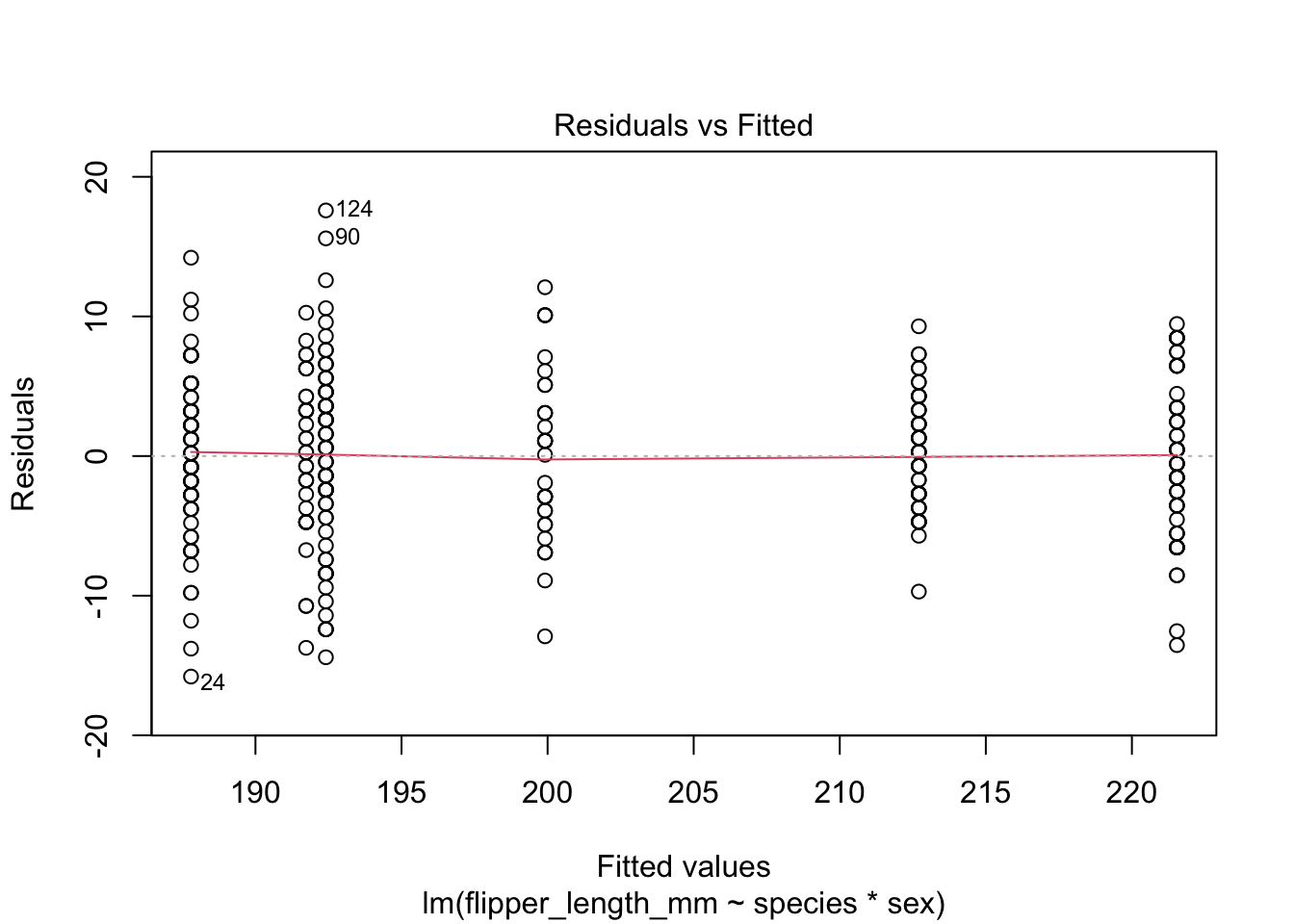
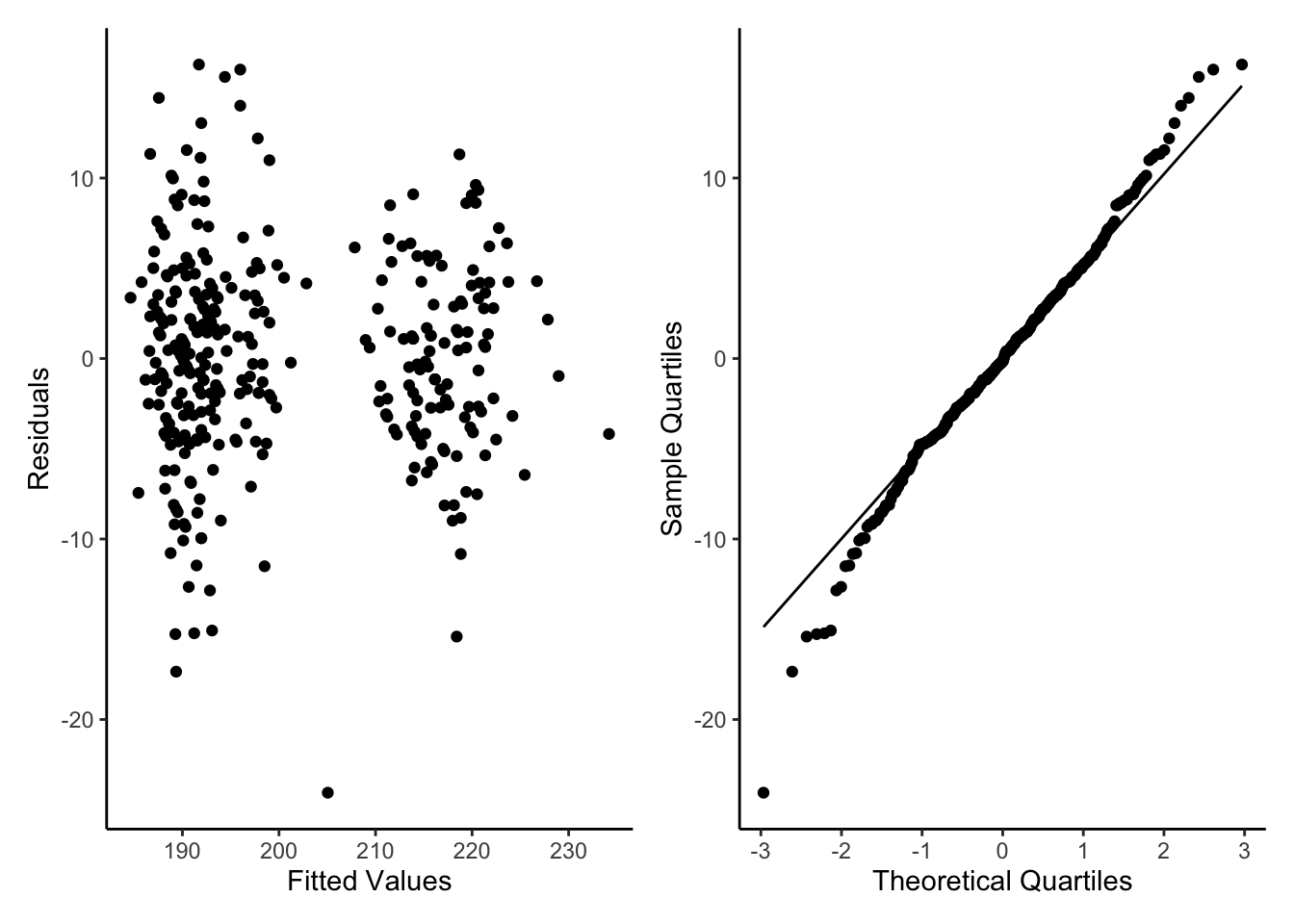
We can now check visually the residuals from our model.
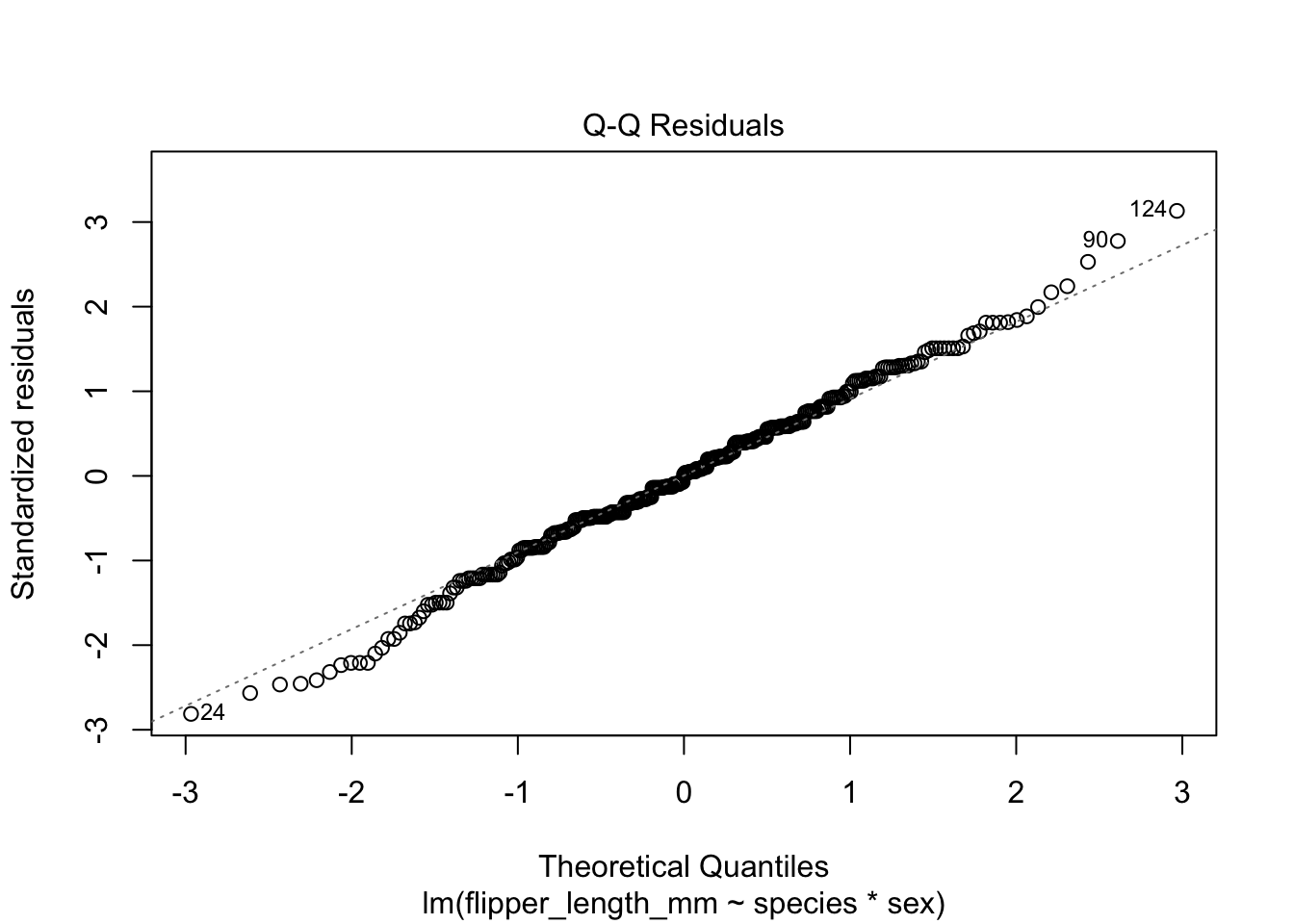
By using the base plot function in 4 we get 4 plots. The first two are the ones we are most interested in generally. The next two plots are less important generally but can be used to find out what is wrong if the first two plots are not as we want them.
For the Residuals vs Fitted plot we want the data to be evenly spread from right to left, meaning the difference between the model and the data (residuals) are not generally larger or smaller at higher or lower values of the model.
The next important plot is the qq plot, this is best if the points follow line of x=y, which is the dotted line behind the points.
plot(lm2.1)
This is annoying as we have to press enter in the console to see all the plots.
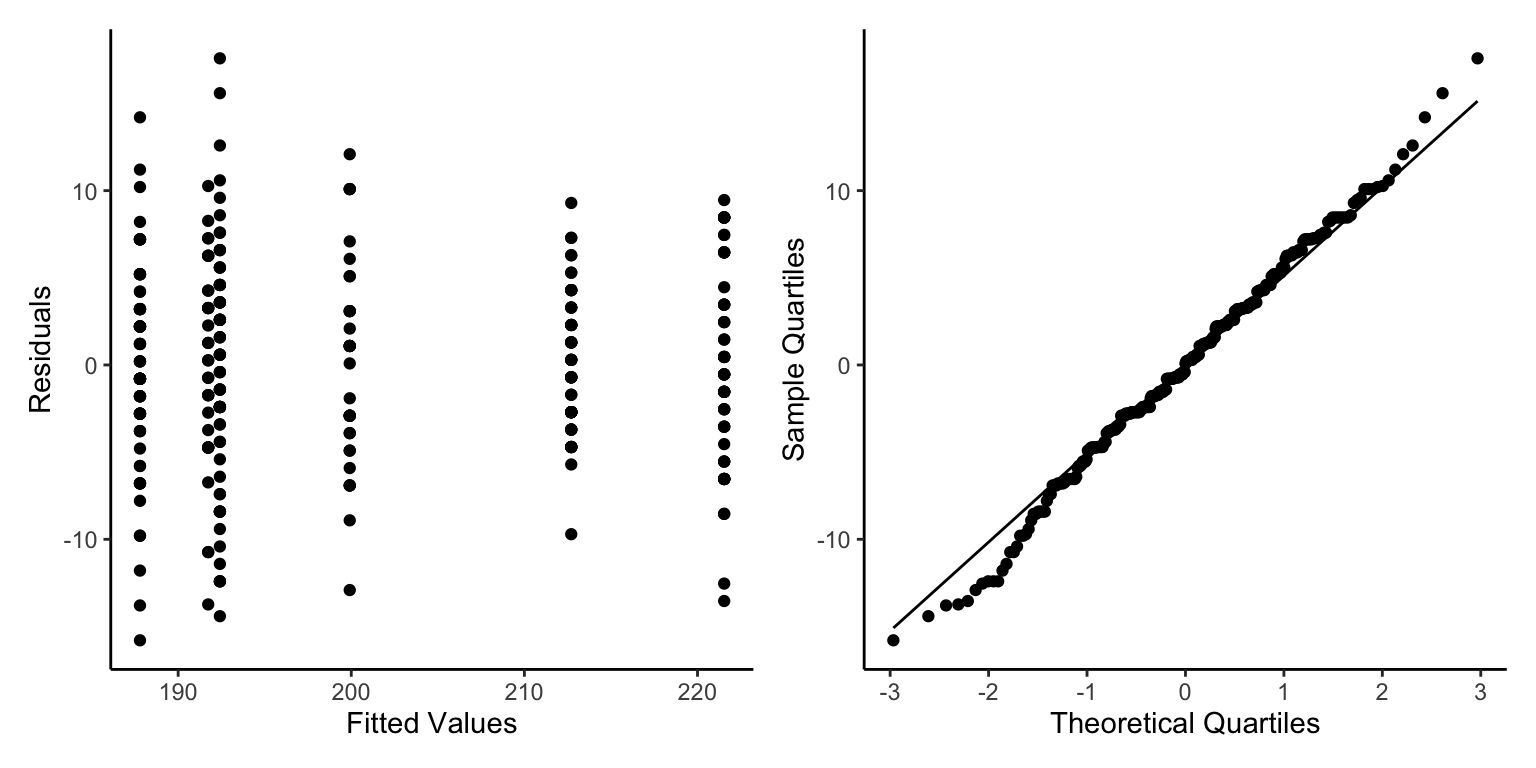
We will code the residuals and qqnorm plots. This is relatively simple code, there are helper functions such as part of the performance package but they are quite unstable from my experience.
As we only have factors in our model we don’t see a ‘cloud’ of points, but the residuals are evenly spread above and below 0 so this is good.
As the diagnostics are good we can look at the results
summary(lm2.1)
Call:
lm(formula = flipper_length_mm ~ species * sex, data = penguins_noNAs)
Residuals:
Min 1Q Median 3Q Max
-15.7945 -3.4110 0.0882 3.4590 17.5890
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 187.7945 0.6619 283.721 < 2e-16 ***
speciesChinstrap 3.9408 1.1742 3.356 0.000884 ***
speciesGentoo 24.9124 0.9947 25.044 < 2e-16 ***
sexmale 4.6164 0.9361 4.932 1.3e-06 ***
speciesChinstrap:sexmale 3.5600 1.6606 2.144 0.032782 *
speciesGentoo:sexmale 4.2176 1.3971 3.019 0.002737 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 5.655 on 327 degrees of freedom
Multiple R-squared: 0.8396, Adjusted R-squared: 0.8372
F-statistic: 342.4 on 5 and 327 DF, p-value: < 2.2e-16
Okay there are a lot of numbers here but what does it actually mean?
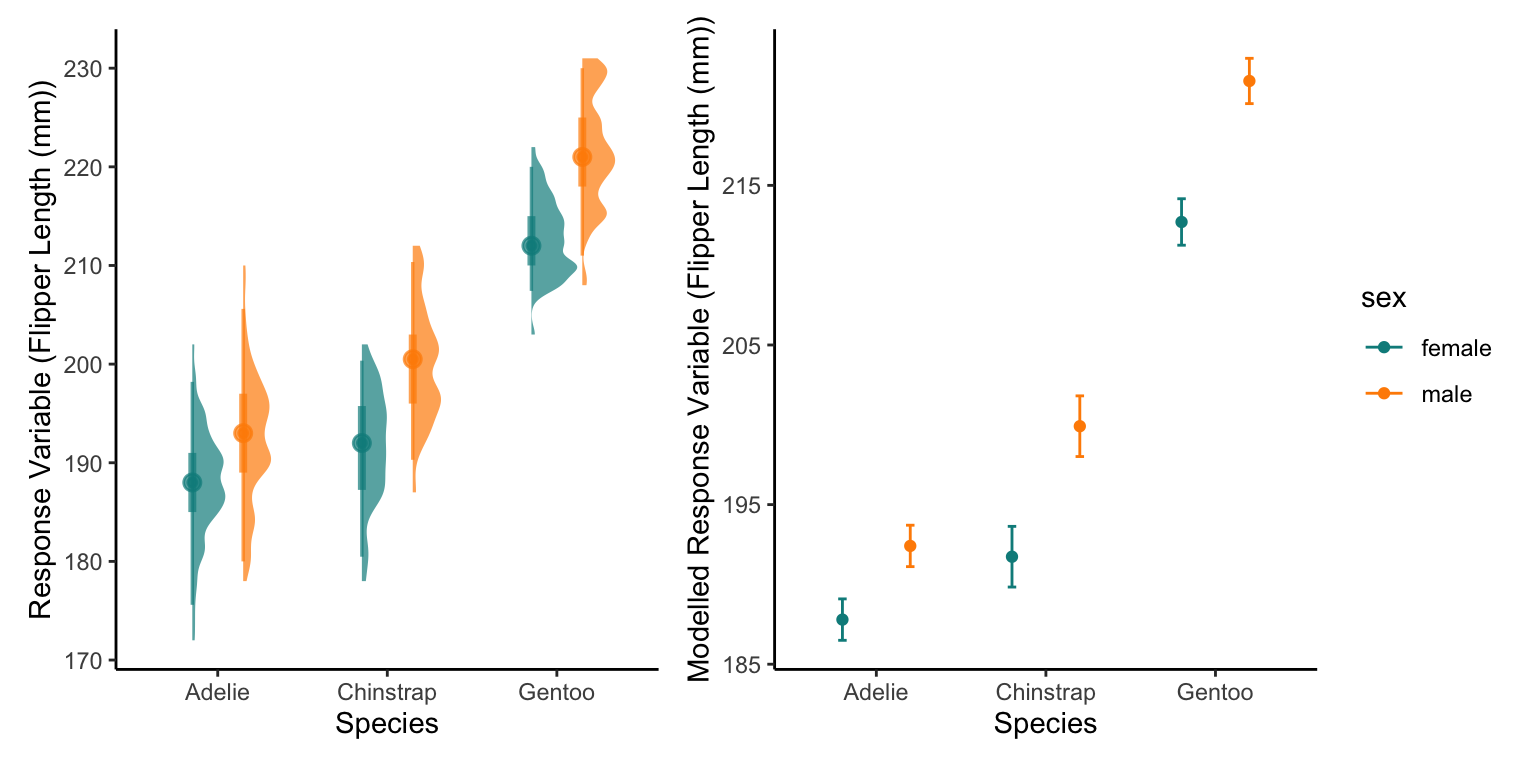
I find the best way to interpret a model output is to plot the model results.
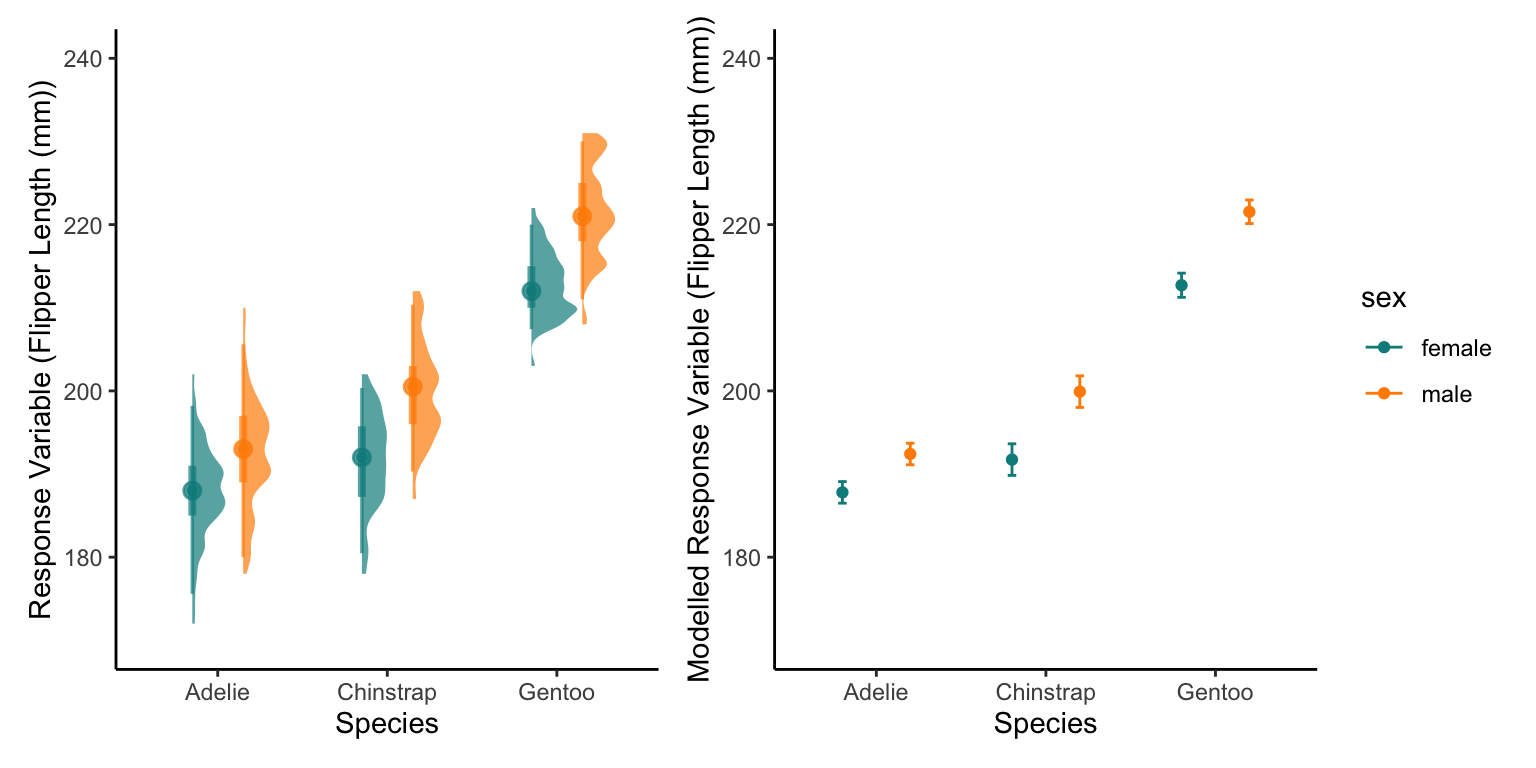
First lets re-plot the raw data, boxplots are probably the best for categorical factors but we could also use a half eye distribution plot. Lets look at both.
The best way to do this (in my opinion) is using the patchwork package that can combine the plots
We create a plot for each, then plot them side by side. Patchwork is a very simple way of combining ggplots together.
We can re-use some of our code from the intro for appearance and colours
As the Gaussian distribution has no data restrictions for the mean value the link function is nothing. Seems silly to include here, and many people wouldn’t, but it will keep consistency for later when we do have a link function.
When we plot the estimates into this equation, this should be similar to our raw data but not identical. Remember we are creating a model to Generalise the patterns of the raw data, not copy them!
Step Five - Model Interpretation
Thankfully we don’t have to extract each \(\beta\) parameter from the summary table as R has useful functions that can do this for us! To do this we make simulated raw data with the same predictor variables in.
We then use the model to predict() the response variable based on those predictor variables.
Therefore, we make a data set with just sex and species the same as our original data (be careful of spelling and capitalisation, R wants it identical).
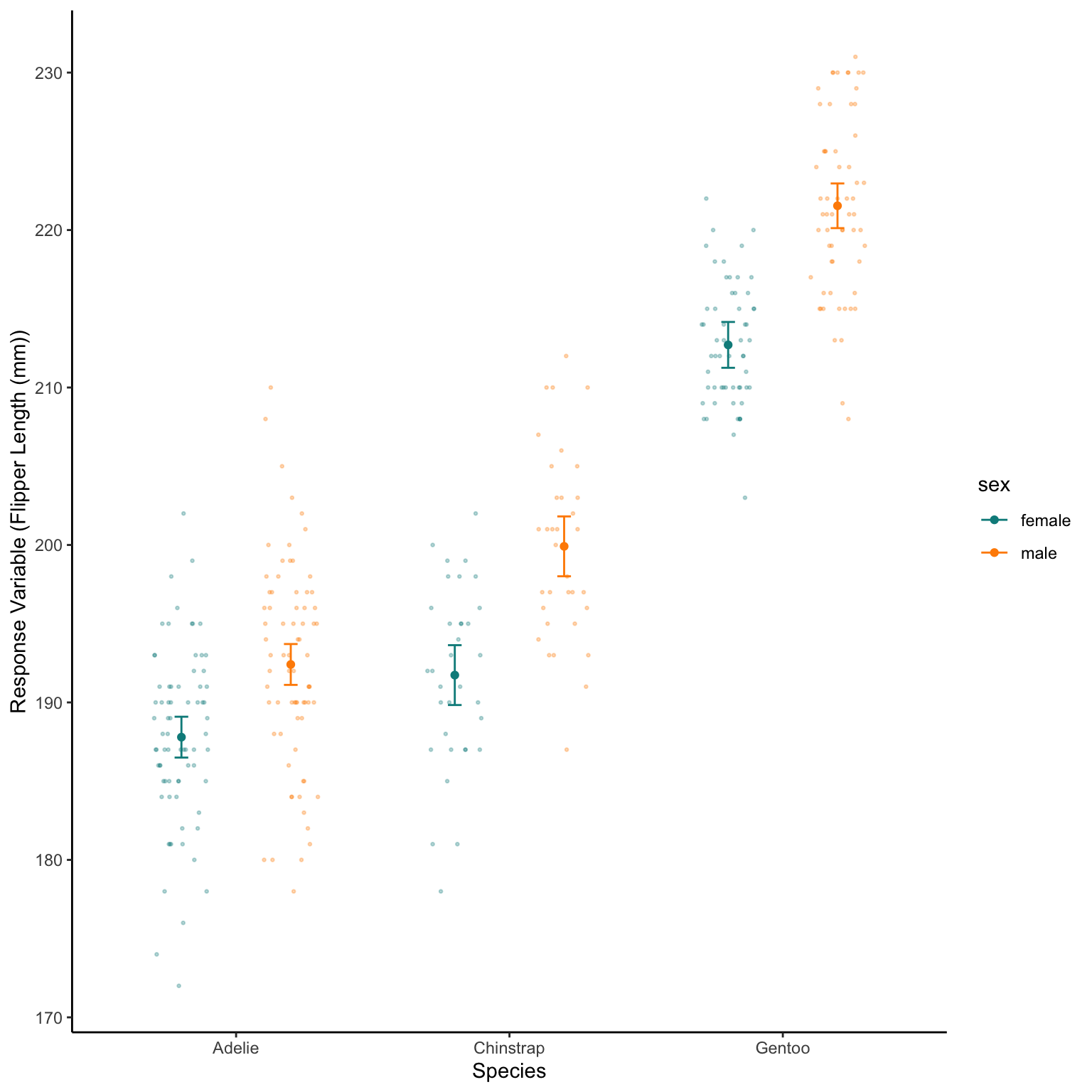
The model then predicts the average Flipper length in mm based on those species and sexes.
We can also tell the predict function to predict error (Standard Error here that we then convert to an approximation of the 95% confidence interval)