library(tidyverse)── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.0 ✔ stringr 1.5.1
✔ ggplot2 3.4.4 ✔ tibble 3.2.1
✔ lubridate 1.9.3 ✔ tidyr 1.3.1
✔ purrr 1.0.2
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errorslibrary(performance)
library(patchwork)
# install.packages("betareg")
library(betareg)
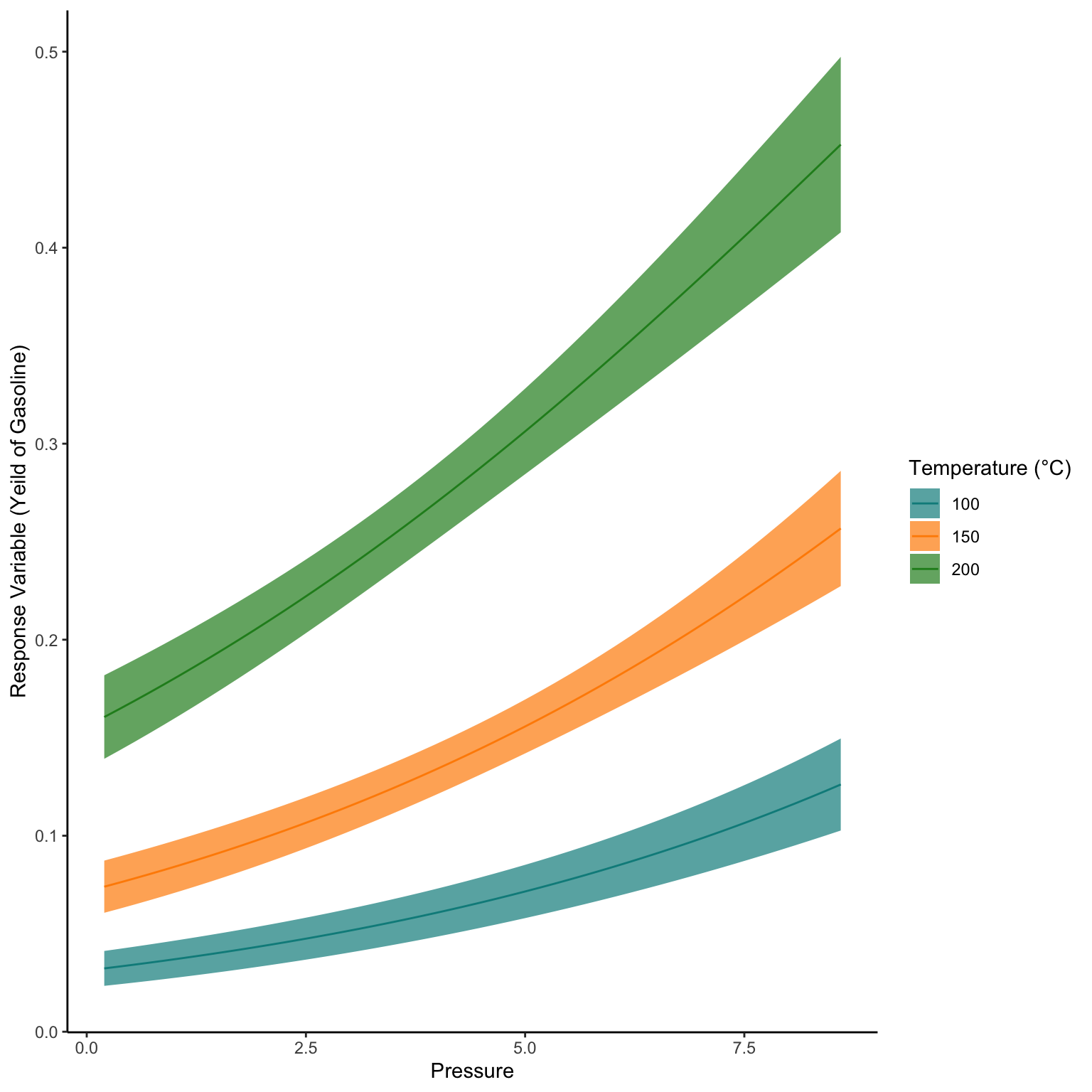
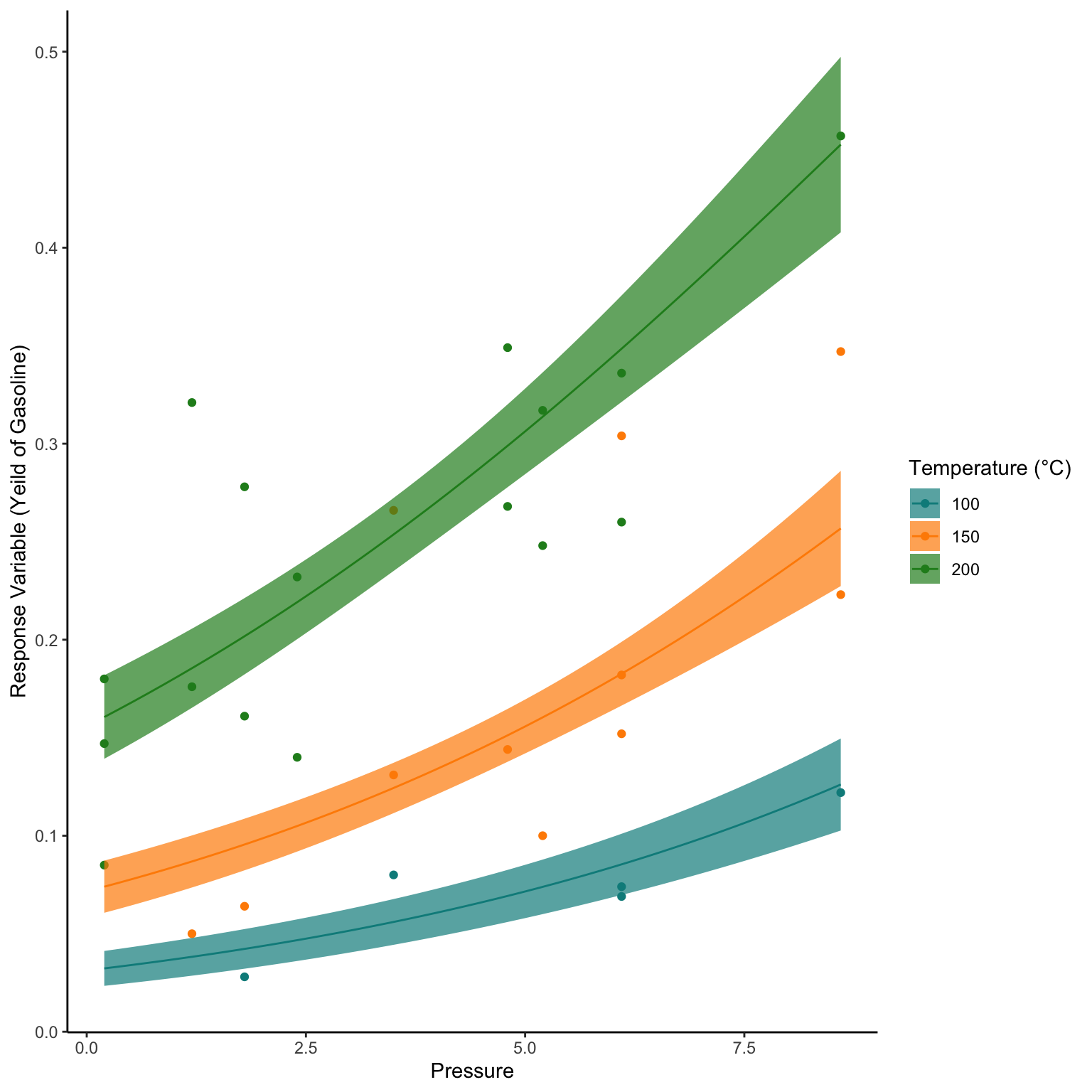
data("GasolineYield", package = "betareg")
glimpse(GasolineYield)Rows: 32
Columns: 6
$ yield <dbl> 0.122, 0.223, 0.347, 0.457, 0.080, 0.131, 0.266, 0.074, 0.182…
$ gravity <dbl> 50.8, 50.8, 50.8, 50.8, 40.8, 40.8, 40.8, 40.0, 40.0, 40.0, 3…
$ pressure <dbl> 8.6, 8.6, 8.6, 8.6, 3.5, 3.5, 3.5, 6.1, 6.1, 6.1, 6.1, 6.1, 6…
$ temp10 <dbl> 190, 190, 190, 190, 210, 210, 210, 217, 217, 217, 220, 220, 2…
$ temp <dbl> 205, 275, 345, 407, 218, 273, 347, 212, 272, 340, 235, 300, 3…
$ batch <fct> 1, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 4, 5, 5, 5, 6, 6, 6, 7…df<-GasolineYield %>%
mutate(temp=(temp-32)*5/9,
temp10=(temp10-32)*5/9)