
Introduction GLMs
Introduction
R
GLMs
An Introduction to General Linear Models (GLMs) in R.
GLMs - Background 
Statistical analysis in r is very easy (on the whole) but needs a bit more background to fully understand. But for most of our situations we will want to use a group of models called General Linear Models (GLMs) or if more complex General Linear Mixed Effects Models (GLMMs). These modelling frameworks plus the additions/alterations from their defaults have lots of different names but in ecology and specifically r the names here are the most commonly used.
Short and Probably Biased History
These modelling frameworks can be used to model almost all situations that will arise in our work. We are almost always using models to describe relationships. We can then use those models to predict future events but this is less common and more nuanced so we might use other tools for that.
In more traditional “Fischer” style statistics there are a wealth of different tests for each different scenario such as t-test, ANOVA, Kruskal-Wallis, Friedman, Mann-Whitney-U etc. These tests were created, designed and developed from work by a researcher called Fischer, with many ecologists/researchers generally holding onto this style as it has been used and taught for decades. However, they were designed and created for very specific cases. This means that they are extremely powerful and useful in those situations but are almost always used in slightly different situations or scenarios and so lose their power.

GLMs and GLMMs can be used in all the same cases as these older style tests as well as many many more. GLMs and by extension GLMMs have the advantage of being more consistency with terminology, have higher flexibility and you do not need to know 1000 different tests to use them. There are important options to chose within GLMs and GLMMs but as I mention they are more consistent and easier to check or adhere to their assumptions.
Side Note - Bayes/Frequentist/Who Cares
Discussion, examples and code here about GLMs and GLMMs will be carried out and more aimed at Frequentist methods of analysis. However, as Richard McElreath points out amazingly in his Statistical Rethinking Course (GO CHECK IT OUT IT IS AMAZING AND FREE!! https://www.youtube.com/@rmcelreath or https://github.com/rmcelreath), the general principles are the same between Frequentist and Bayesian methods, the important part is interpretation and building scientific and statistical models to allow Causal Inference! (i.e. does the model actually provide us with evidence of a cause and if so what is that cause.)

What are GLMs?
Effectively General Linear Models are ways of creating generalising lines or linear equations that best describe the data we put into them given some equation of interest.
We can summarise most with three equations. We have the linear equation \(y = \beta x + c\) and how that relates to the data we sample (\(s\)) \(s = Distribution(y,\sigma)\) .
This will often be written generally as:
\[s = Distribution(y',\sigma)\]
\[y'=f(y)\]
\[y = \beta x + \alpha + \epsilon\]
The first of these equations (the distribution equation) is saying that the data we sampled (\(s\)) comes from some distribution, with certain shape parameters (\(y'\) and \(\sigma\)). \(y\) is the result of an effect (\(\beta\)) multiplied by some fixed effect (\(x\)) and an intercept value (\(alpha\)). Between these two equations we have a link function (\(f()\)). This converts \(y\) into a value that the distribution function will accept \(y'\), again we will define what these elements are later. The elements that we want our GLM to tell us is the effect of x (\(\beta\)) and the intercept (\(\alpha\)). We don’t have to do maths at all for GLMs but it can help some people understand what the model is telling us. (If you don’t like equations/maths ignore this bit - But we will discuss link functions later on).
First Step of Analysis - Statistical Model Formulation
Generally we will have a response variable (Dependent Variable) with one or more fixed effects (independent variables).
Here I will discuss exclusively univariate modelling (where only one variable is the response variable) but multivariate analysis could follow the same framework, it is just more complicated to implement.
Our research question will dictate how we create our scientific model, which dictates what statistical model to use and then how we interpret that statistical model.
Many researchers like to draw out what is called a DAG, which diagrammatically shows assumed influences of factors, and the directionallity of that influence. At first these are quite difficult to formulate until you have created a few. Therefore, the easiest way I can think to do this is saying some sort of hypothesis or statement in English then we can turn that statement into the Statistical model.
For example: I hypothesise that the flipper length of a penguin is described primarily by the species of that penguin but also influenced by its sex. Effectively Flipper length changes with Species and Sex.

Here our response variable is Flipper length (Dependant variable) and our fixed effects (Independent variables) are Species and Sex.
In statistical notation we could write this in a couple of ways depending on our assumptions:
1). flipper_length_mm ~ sex * species
2). flipper_length_mm ~ sex + species
Firstly, we see on the left hand side of the ~ (tilde) we have our response variable, with our fixed effects on the other side.
Secondly, we see that we either multiply or add these fixed effects. The difference between the two is subtle but important.
Equation 1 is saying that flipper length is effected by species and by sexes but that the effect of sex is different depending on the species. (females always bigger in one species but males always bigger in another but one species is always much larger than the other).
Equation 2 is saying that flipper length is effected by species and by sexes but that the effect of sex is the same or similar regardless of the species. (males always bigger across all species, but sizes different across species).
We may think either equation is correct given our knowledge of penguins.
Second Step of Analysis - Response Variable Distribution
The next most important element is what type of data our response variable is. This is the step that is often carried out wrong and leads to many inaccuracies of analysis.
When modelling we are using our sample to make inference about a population. Therefore, our model should be based on our assumptions of the population that we took the sample from.
The type of data your response variable comes from may not be exactly what your response variable data looks like! However, if we have sufficiently sampled the population and not introduced any selection or sampling bias we should be confident in saying our sample (response variable) comes from the distribution of the population. We should be aware of this when analysing data from specific geographies or demographics etc!!!
So we should be able to tell the type of response variable data before we even collect the samples themselves! WE SHOULD NOT LOOK AT A GRAPH OF OUR DATA AND CHOOSE THE DISTRIBUTION IT COMES FROM JUST BY THE SHAPE!!!! (Speaking from experience and errors made!)
Distributions
There are a group of widely used distributions that will cover almost all situations.
They are:
Gaussian
Beta
Gamma
Poisson
Binomial/Bernoulli
There are many, many, many others such as Student-t or Direchlet or Tweedie. All of which are very useful and utilised throughout science but we won’t go through them here.
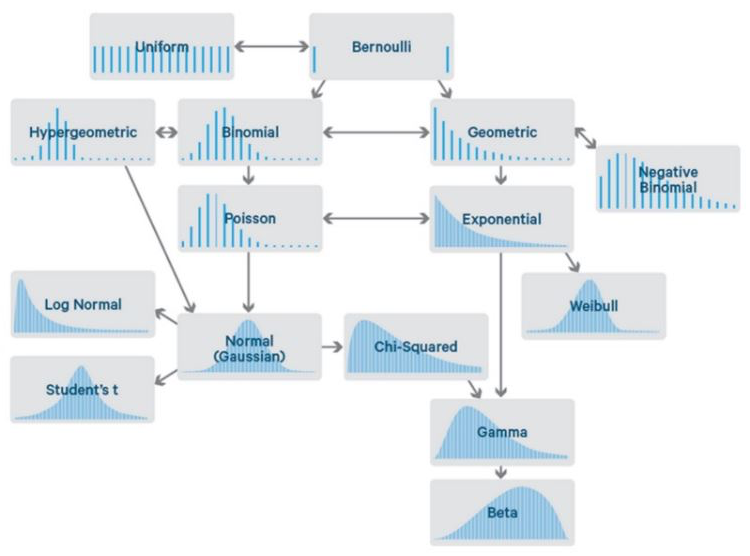
Which to Choose?
Numeric or Categorical
So when deciding what type of model to run we can first think whether our data are numerica or categoric. We will only discuss numerical data (temperature or weight or numbers of fish) but sometimes we might have a categorical response variable, such as questionnaire answers. Within these types of model there might be order to the categories (Not likely, Somewhat likely, Very likely) or there is no logical order (green, blue, purple). There are mixed effects models for these that are widely used, such as Multinomial Logisitic Regression for non-ordered and Ordinal Logistic Regression for ordered categorical response variables, but again we won’t discuss them here.
Numeric: Continuous or Integer
Once we know our data are numeric, we need to choose what type: continuous or integers. This is quite an easy one, can you measure it in decimals or is it complete units. When studying nesting birds we don’t count half eggs; a nest will have 1, 2, 3 etc. eggs. But if we are measuring the width of a tree it might be 4 cm or 2.365441 m.


Continuous: Can the data be Negative?
Once we know our data are continuous numeric, we can think can the values be negative? A response variable that is continuous and can be negative is mostly modelled under the most common distribution: Gaussian. Examples of this could be temperature measured in \(^\circ\)C or acceleration. A response variable that cannot be negative or even 0, would most correctly be: Gamma. However, Gaussian models are very often used for these models as a Guassian distribution is simpler computationally and mathematically, and only really causes issues when the values approach 0. This is actually most continuous values we measure, such as thickness of a stem, fish length, body mass or area of habitat.
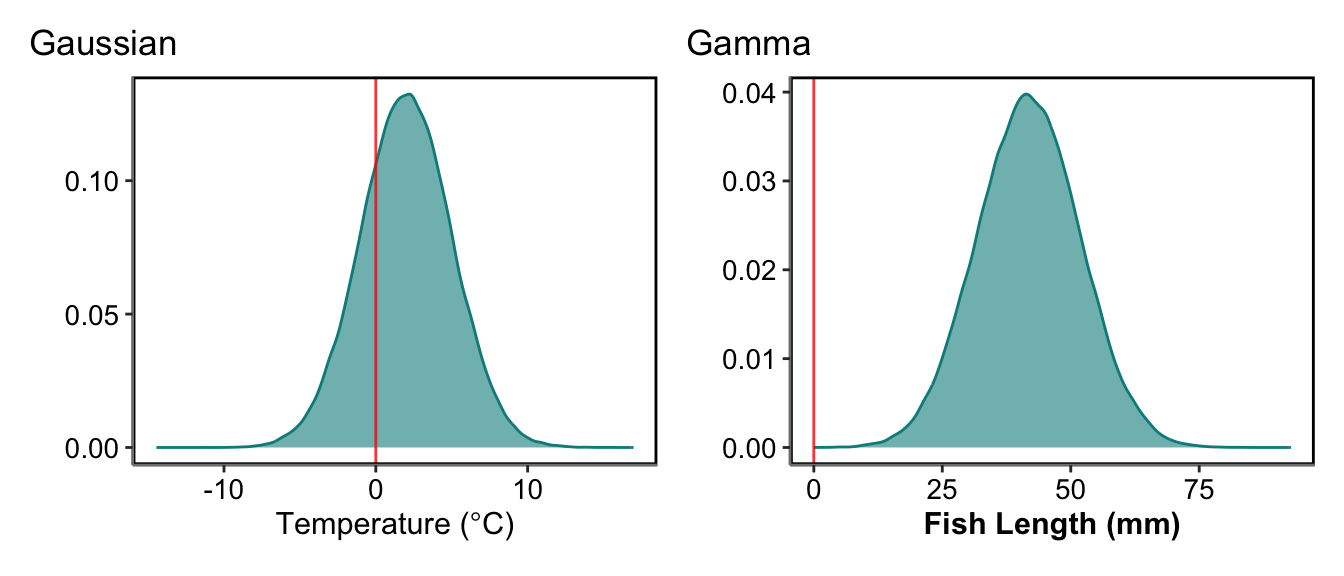
Continuous: Are the data bound between two values?
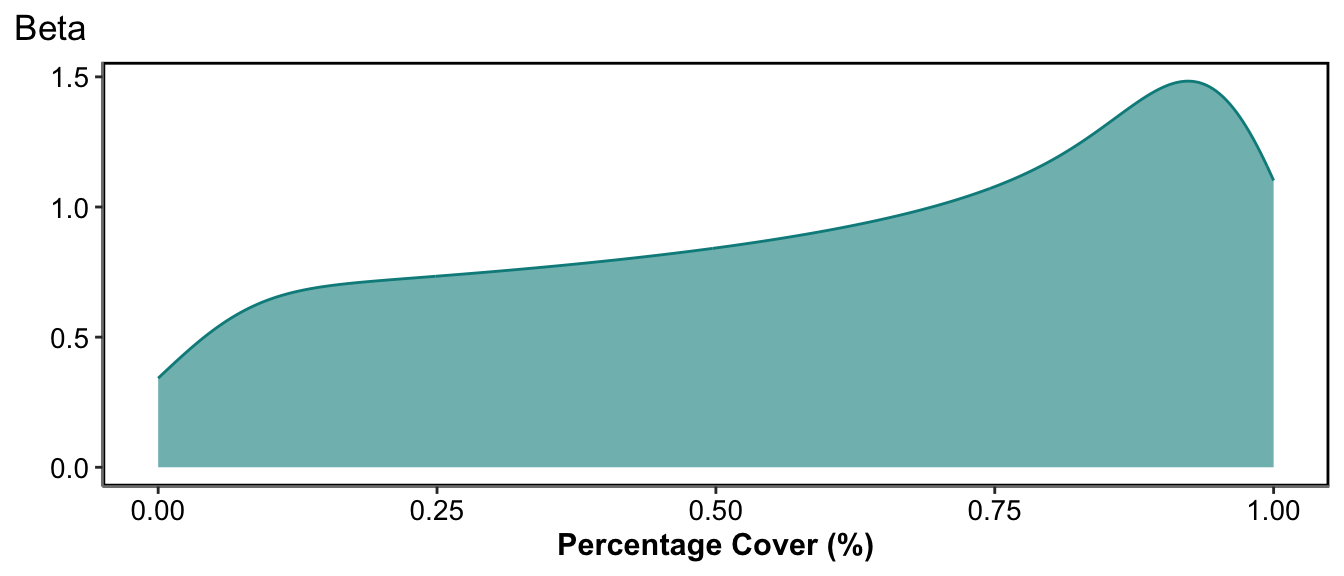
If your response variable is continuous, and it may be negative or not, but is bound between an upper and lower known bound then it would most correctly be: Beta. For most practical terms Beta distribution is between 0 and 1. However, most data between bounds could be scaled to 0 and 1 and keep all of their characteristics. For example, percentage or proportional data are effectively between 0 and 1 and can be modelling using a Beta distribution.
Integer: Known upper limit or not?
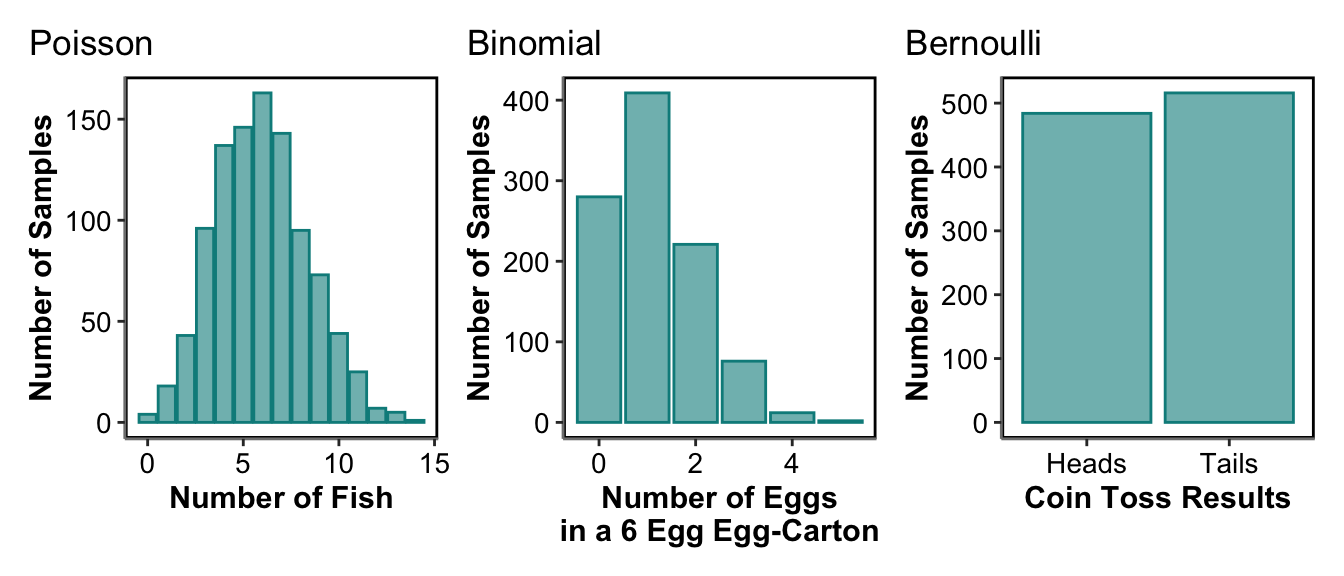
We know our data are integers but do we know whether there is an upper limit? If our data could potentially be very big as counts then we will use the Poisson distribution. This is for response variables like number of eggs in a nest or abundance of fish or the number of different species found along a transect. If we know there is an upper limit to the integers we could get then we will use a Binomial model. This could be for the number of eggs inside a six egg carton. The most common version of this is when we have a binary response variable (either 1 or 0). Presence or absence of a rare species for example. This is binary Binomial but is sometimes referred to specifically as Bernoulli.
Third Step of Analysis - Organising Fixed Effects
We now know what distribution we will most likely use to analyse our response data, so the next step is organising our fixed effects so the model treats them how we would like them to be treated. Effectively fixed effects are either numeric or categorical variables. With GLMs there is no different name (nor changes in code) generally used for what combination of numeric or categorical variables are used. So we could have multiple numeric effects, multiple categorical factors or a mixture of both.
Numeric Fixed Effects
In r numeric effects are quite straight forward, “what is the effect on y with a one unit change of value of x?”. However, if our numeric column has really big values, big range and a skewed distribution we may have issues with our model not working or running as we expect. For fixed effects this is easy to overcome, generally we would use some sort of transformation that maintains the structure of the data but minimises the issues the model runs into.
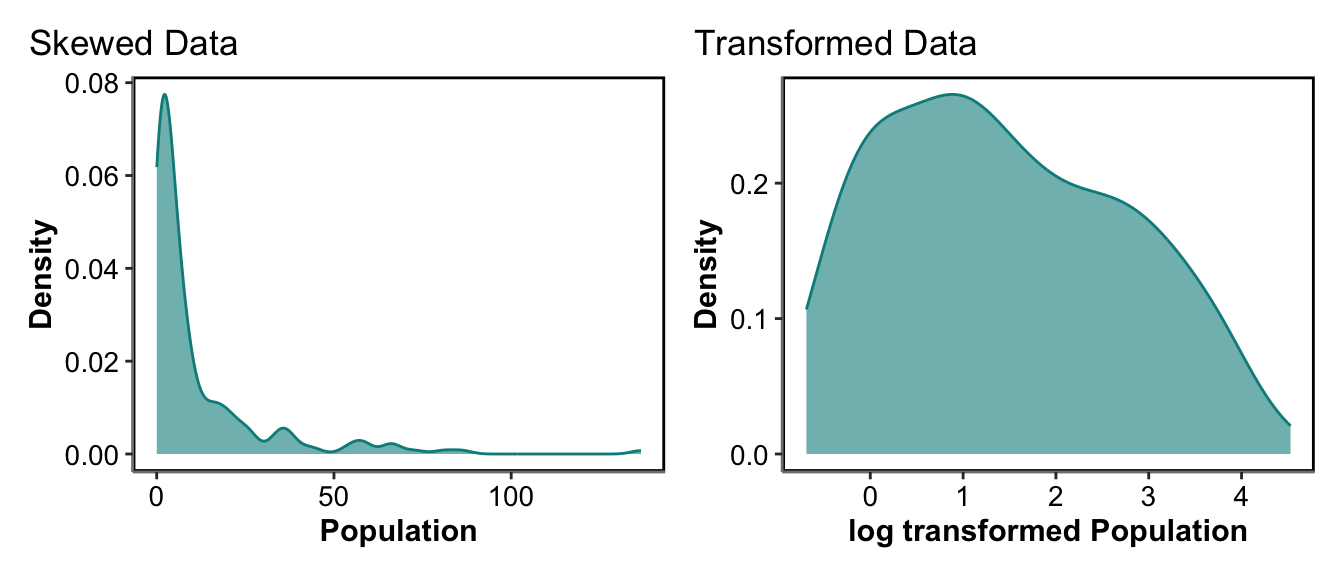
- Skewed Data
For example for skewed data, if our fixed effect was based on population size with the nearest 2 km, we may have some seriously big values in cities and seriously small values in the countryside. For these data we may use a log transformation, or a square root.
- Overly Large Data
If our fixed effect was a really big value but actually we are interested in small changes we might consider it differently. For example we might look at Year, in our data that would be above 2000 generally but actually if we have 5 years of data we are looking at it would be easier for the model to convert our data to year 1, year 2, year 2 rather than 2020, 2021, 2022. Here we maintain the difference of 1 year between each value so change the scale.

- Awkwardly Placed but ‘Nicely’ Distributed Data
Sometimes we may have a distribution of values that is ‘nicely’ distributed, with a clear mean, most values centered on that mean with less values further away from that mean. But if that mean is quite large, or really really small, or really really negative we may have issues with models not working correctly. This can also occur when we have more than one fixed effect and they are on very different scales. For example, body measurements as fixed effects where one body measurement is on the scale of metres and another is millimetres. For these we can centered and scale, sometimes call normalise, our effect by subtracting the mean from every value and dividing by the standard deviation.
Categorical Fixed Effects
Categorical factors can be less simple. R takes the first level of the categorical effect as the baseline or reference state, then compares all others to that one reference level. If you only have two levels then that is fine, the model will tell you the effect of changing from state 1 to state 2. This is directional. However, with more than two levels the results in r will only tell you the pairwise comparisons from state 1 to state 2, state 1 to state 3, state 1 to state 4 …. state 1 to state n. This is harder to interpret in the results table but if you plot the model it becomes easy. It does mean that we can make sure if there is a control or base level in our factor we can use that as our reference level. This is done by ordering our column so that our desired base level is first in the column. If the column is a character style data r will use the first level alphabetically as our reference data. Sometimes we won’t care though, we just have to be aware that it is happening.
Fourth Step of Analysis - Assessing Model Functioning
GLM/GLMM Assumptions
GLMs and GLMMs have some broad assumptions for them to be appropriately used. Regardless of the distribution type an Independence of sample is assumed as well as homoscedasticity and normality of residuals is assumed.
If we have created an appropriate statistical model that takes into consideration the heirarchy/structure of the data our samples should be independent.
So what are residuals and what is homoscedasticity?
Homoscedasticity of Residuals - Fitted vs Residuals Plot
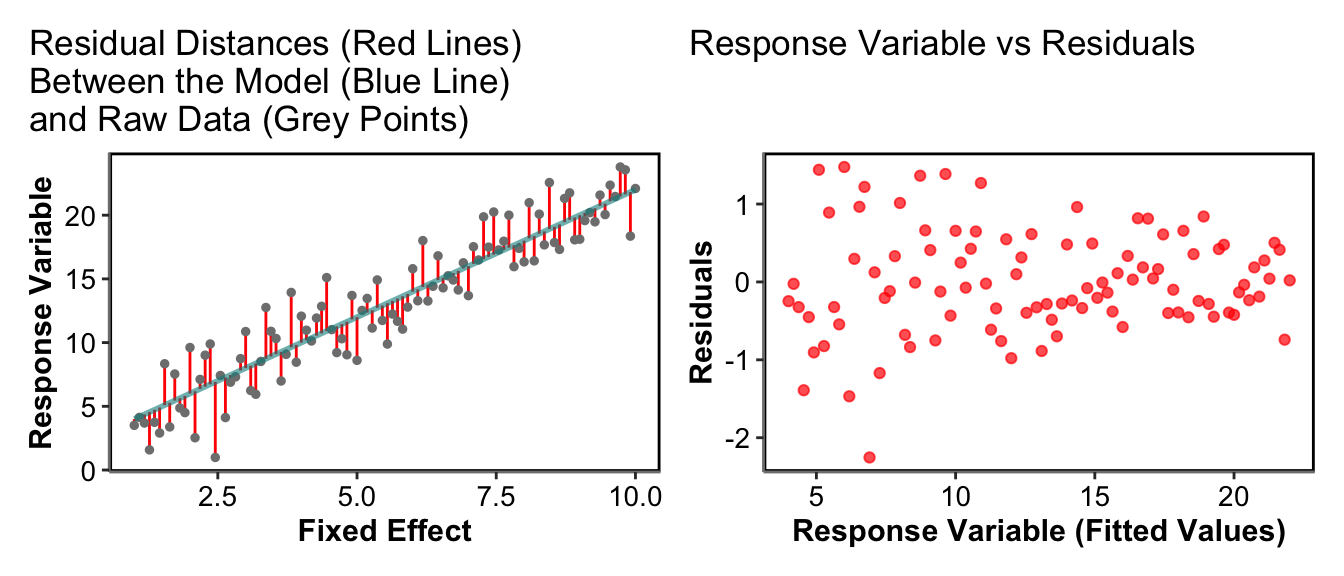
To assess the assumptions of our models we can look at the residual distance between the model line and the points, these are called the residuals of the model.
In its most basic version the residuals are the distance between the model and the raw data, then the plot of those residuals against the fitted values (or our response variable) can show how the sizes of residuals change across the fitted values. Homoscedasticity means homogeneity of variance or that the variance is consistent across the whole range of data. Therefore, ideally we want the residuals to represent a cloud of points with no clear patterns across the range of the response variable (fitted values), this is very subjective but a useful qualitative assessment of how good our model is. If our model was missing a clear pattern in the raw data then we would see a clear pattern in the residuals.
If we see patterns in our Response Variable vs Residuals plots (not just a random cloud of points) this may mean we missed an important fixed effect in our model (Underlying structure of the system has been ignored), the data do not come from the assigned distribution, there are a high number of zeros in our data or the data do come from the correct distribution but we have been biased in our sampling method (There could be many other reasons but these are the main ones).
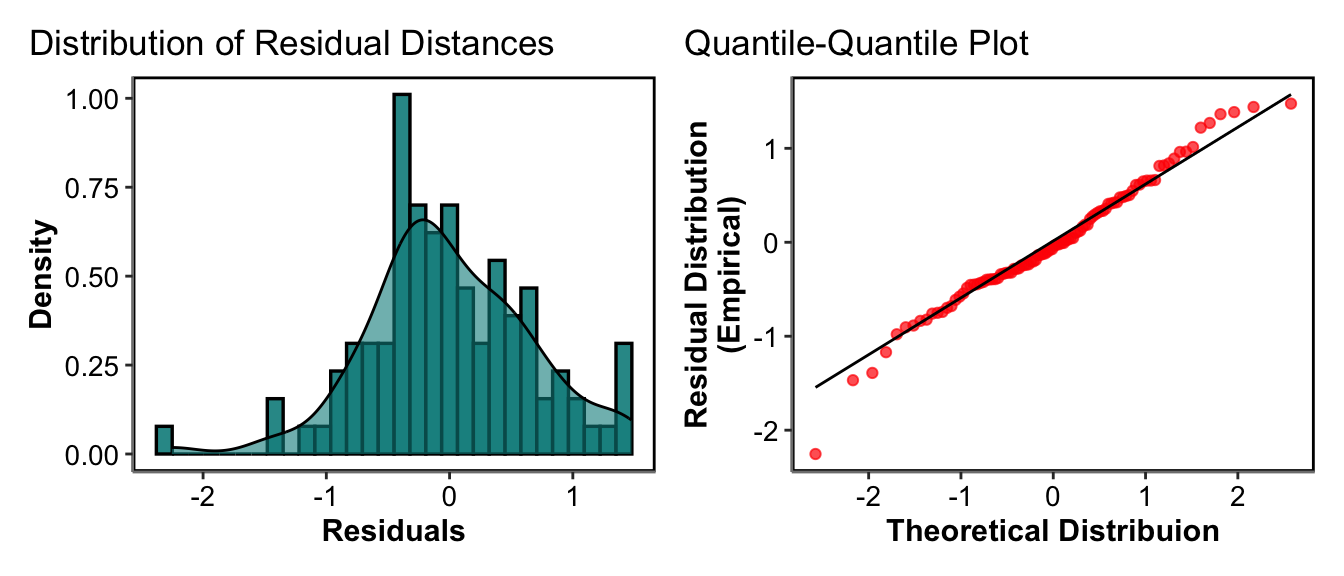
Normality of Residuals - Quantile-Quantile Plot
For the vast majority of GLM and GLMMs, there is an assumption that our residuals are normally distributed. Basically this means that our residuals have a mean distance from the model and most of the values are around this mean. Then the likelihood or probability of having much larger or much smaller values than the mean becomes smaller and smaller. We can therefore plot our residuals as a histogram to see if it follows a generally normal or bell shaped distribution. We can also do what is called a Quantile-Quantile plot, which creates a theoretical distribution of values given the data range, then plots it against the empirical or true distribution. If the residual distribution are perfectly the same as the theoretical distribution it follows a 1 to 1 line (y=x). Again these are more qualitative checks where some variation and divergence from normality is fine.
Fifth Step of Analysis - Model Interpretation
Once we are happy with our model, we can assess what the model tells us about our data. Our interpretation of the model will depend on the statistical model we used and the assumptions we made about our raw data. The best way to interpret a model, once we are happy with it, is to plot the model. To do this we can simulate data that covers the range of our fixed effects, then use the model to predict our response variable for all the values of these fixed effects we simulated. As a final check of how well our model has Generalised the patterns of the raw data we can also plot the raw data alongside our modelled data.
